炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
来源:石头科技视频博客
大家好,本次我们将对全网13款大语言模型进行全面测评,揭示哪款性能最为出色。
首先公布测评结果:综合能力最强的依然是GPT-4。除综合能力外,我们还测试了写作、数学、信息提取、编程等多项能力,这些将在后续视频中详细分析。
本期文章内容分为三部分: 1. 各模型的基本介绍
2. 大语言模型的工作原理
3. 详细的测评流程
我们先来了解这些模型。GPT-4由国外公司开发,该公司虽然不是大语言模型的开创者,但却是最早向公众开放使用的商业公司。其次是Claude Opus,同样来自国外公司,与Claude Sonnet同属一家。官方宣称Opus性能更强,Sonnet稍弱。GPT-4与GPT-3.5也属于同一家公司。
为便于理解,部分模型名称我们进行了中译,同时保留了英文原名以避免歧义。国内公司的模型则直接使用中文名称。
文心一言4.0与文心一言3.5均为百度公司旗下产品。
讯飞星火,顾名思义,是讯飞的产品。智普AI则属于智普公司。360超级智脑由360开发。双子座精英版和双子座是谷歌的模型。此外,腾讯混元和通义千问也是两个独立的模型。这些模型的信息均可通过互联网查询,此处不再赘述。
接下来,我们简要探讨大语言模型的原理。许多人认为大语言模型非常神奇,甚至担忧其可能产生自我意识并取代人类。实际上,这种情况不太可能发生。让我们从数学函数的概念讲起。
以函数为例,给定任意输入,都能得到相应的输出。例如,当时,。这种对应关系称为函数。
大语言模型本质上是一个极其复杂的函数。其工作原理是:将输入文字转换为数字,经过这个复杂函数处理后,生成新的数字序列,再转换回文字输出。有人可能会问,文字如何转换为数字?以英文为例,可以用1代表A,2代表B,以此类推。中文虽字符众多,但理论上也可用数字编码表示,尽管实际应用中这种方法效果欠佳。
文字数字化后,这些数字被输入到一个极其复杂的函数中运算,最终结果再转换回文字。这就是大语言模型的全部工作流程。它没有自我意识,也不理解语言含义,仅仅是基于数学函数进行数字转换和计算。
人工智能无法取代人类,也不具备自主意识。有人可能会质疑量变是否会引起质变,但答案是否定的。因为其本质只是一个函数。例如, 是一个简单函数, 稍显复杂, 则更为复杂。但无论函数多么复杂,都不会产生自主意识,也不可能取代人类。大语言模型同样如此,既不会产生意识,也不会对人类构成威胁。
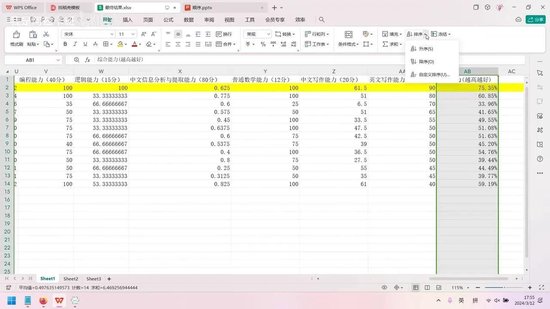
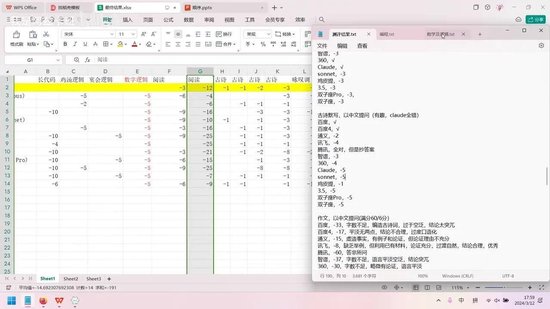
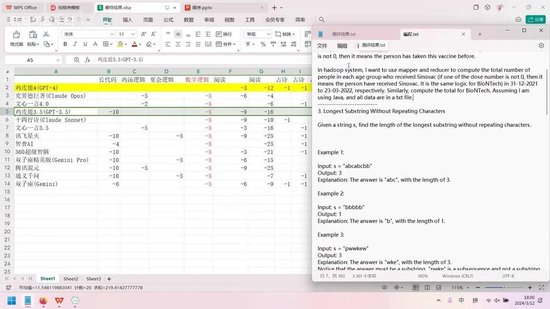
接下来分析具体能力维度。本次测评主要考察了编程能力、逻辑能力、中文分析能力、数学能力、中文写作能力和英文写作能力。在众多模型中,GPT-4表现最为突出,其编程能力与Claude Opus、文心一言4.0并列满分。其他模型存在一定差距,其中通义千问、双子座精英版和360超级智脑表现较差,智普AI排名垫底,但在其他方面有所弥补。
需要说明的是,本次测评仅针对官网开放且存在价格差异的模型,目前展示的样本数量有限。
此外,还有一些未展示的内容,但均已进行测试。所谓官网开放,以文心一言为例,文心3.5和文心4.0均在官网开放使用。
我未购买普通会员,而是选择使用百度平台的文心4.0。普通会员存在使用限制,每月额度有限,用尽即止。因此,我更倾向于购买开发者平台,采用按量计费的方式。后续内容均可在该平台获取。
对于没有价格差异的模型,我没有进行测试。例如360智脑,它提供了多个对话角色,包括360智脑、埃隆·马斯克和超级智脑,这些功能都是免费的。由于没有价格差异,我选择了看起来功能较强的超级智脑进行测评。同理,智谱AI也是如此。
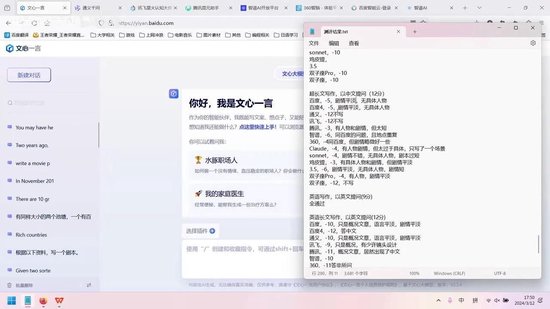
这是我之前的测评记录。该平台提供了多种模型,目前均免费开放使用。因此,我测试了官方宣称性能最强的GLM4模型。但部分模型如文心一言4.0,其具体评分标准如下。
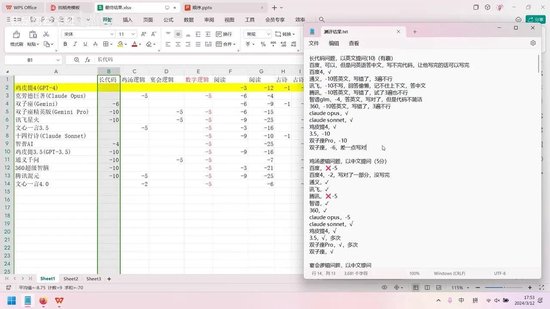
文心一言3.5与其他模型存在价格差异,因此我对两者都进行了测评,以评估其性价比。
在逻辑能力方面,GPT-4表现最优,双子座Gemini次之,Claude Opus稍显逊色。
文本分析能力的排名较为特殊,文心一言在中文信息分析中表现最佳。由于缺乏合适的英文素材,本次仅测评中文分析能力。Claude Opus在此项表现良好,百度和通义千问也表现优异,但仅限于文本分析。GPT-4的表现尚可。
在普通数学能力测试中,各模型表现相当,并列第一。
中文写作能力方面,GPT-4意外夺冠,百度以0.5分之差紧随其后,其他模型表现明显落后,双子座Gemini仅得6.5分。评分采用百分比制,满分为15分,但具体分值并不重要,重在相对比较。
英文写作能力的差距更为显著。GPT-4领先,Claude Opus次之,双子座Gemini两个版本随后,讯飞星火和文心一言表现较差。
文心一言4.0的英文写作能力表现不佳,主要原因在于其生成内容多为中文。这一点我们后续会详细讨论,腾讯混元也存在类似情况。最后我们通过计算各项指标的平均值得出综合能力评分。
具体计算过程如下:首先评估代码能力,我们采用了一个长代码问题作为测试用例。
从这里开始内容较为繁琐,不感兴趣的读者可以跳过。
现在已过去13分钟。关于长代码部分,我就讲到这里,感兴趣的可以自行查看。这些题目中英混合,旨在测试模型的综合能力。对于GPT和Claude等模型,它们在中文和英文上的表现都非常出色。其他语言未进行测试,原因是我个人不熟悉这些语言,且大多数人可能同样如此。
接下来,我们不看长代码,先看一个有趣的逻辑问题——数字逻辑题。这个题目原本少了一个减5分项,现在看看调整后评分是否有变化。综合能力评分基本保持不变。有趣的是,减5分后,双子座的表现变为最差,这与其一贯表现相符。
数字逻辑题是一个猜数字游戏,来源于网络。题目中未标注的部分表示未扣分,已标注的则是扣分项。
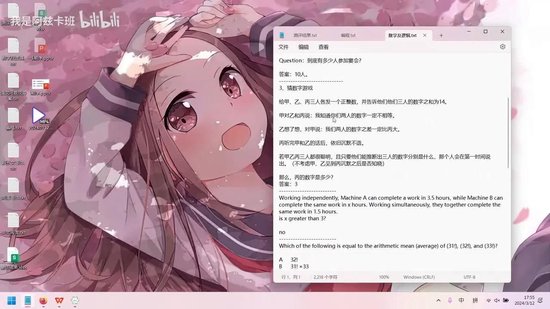
这是一道来自搜狐网的题目。题目描述如下:
向甲、乙、丙三人各发一个正整数,三个数字之和为14。甲对乙和丙说:“你们的数字一定不相等。”乙对甲说:“我们俩的数字之差一定比丙的数字大。”而丙始终保持沉默。
需要注意的是,三人都非常聪明,只要能够推断出各自的数字,就会立即说出来。这道题的难点在于此。题目附有解析,但我没有复制过来。感兴趣的同学可以自行搜索查看。
我记得可以直接用这段话在百度上进行搜索。
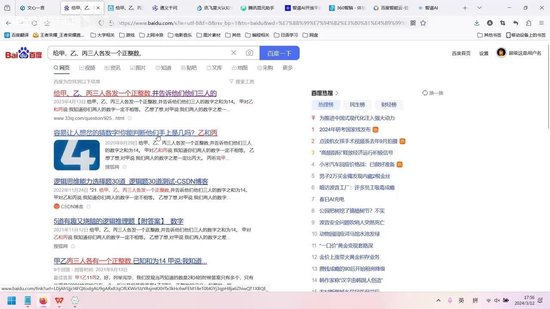
可以通过搜索获取相关信息,此处不再赘述。
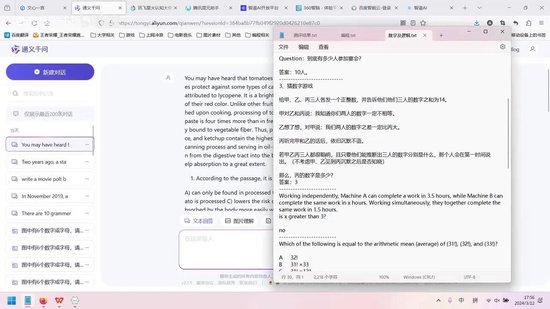
这个问题确实颇具难度,我经过长时间思考仍未得出答案。
只有GPT-4模型能够答对这个问题,但并非每次都能答对。其他模型经过多次测试,均未能答对,可见GPT-4的逻辑能力确实非常出色。
接下来我们分析长代码问题。这段代码本身并不复杂,难点在于其中一句存在歧义的语句。这种设计是为了模拟现实中的复杂问题,因为实际场景中不可能每句话都表述得非常清晰。虽然这句话的歧义并不严重,对人类而言理解起来毫无困难,但对AI来说却极具挑战性。例如“早上叫姐姐,晚上姐姐叫”这样的句子就存在明显歧义,人类可以轻松理解,但对AI的分析能力是很大考验。最终只有少数几个模型能够正确完成这个任务。
智谱AI和双子座Pro接近完成但最终失败。在后续的鸡汤逻辑和宴会逻辑测试中,大多数模型表现良好,但令人不解的是Claude居然无法正确回答如此简单的鸡汤逻辑问题,而许多小型模型反而能够答对。
古诗默写测试中,百度表现最佳,其他模型存在不同程度的错误。GPT-4也表现不错,仅错一处。Claude在这个环节完全无法作答,14行诗测试同样失败,显示出该模型仍存在明显缺陷。
以下是几道阅读题。
这些题目均选自历年语文考试真题,来源于网络。如需测试,可私信获取相关文件。
在阅读能力方面,讯飞星火等模型表现欠佳,主要原因是其处理长文本的能力有限。当文章超过1000至2000字时,这些模型往往无法正常工作,或者难以保持上下文的连贯性。以GPT-3.5为例,它在回答问题时经常无法完整回应,导致评分较低。
举例来说,假设我们需要进行超长文写作,根据现有资料撰写剧本。这些资料均来源于网络,内容较为冗长。多数模型仅能对文本进行简单总结,而无法准确记忆并执行“撰写剧本”的指令,这充分考验了模型的上下文记忆能力。
在测评中,360、质朴AI和双子座的表现相对较差。数学部分尤为有趣,但未纳入最终评分,因其难度过高。题目包括一道函数求导及极值问题,以及一道三角函数问题,均源自网络原题。这两道高考难度题目对多数人颇具挑战性,答案已附于文末。
第八号模型是讯飞火星和360智脑,它们碰巧答对了一个问题。然而,由于题目难度过高,我认为这次结果缺乏参考价值。后续重新提问时,它们的答案又出现了变化,因此我并未将此次结果纳入评分体系,并特别标注了红色标记。
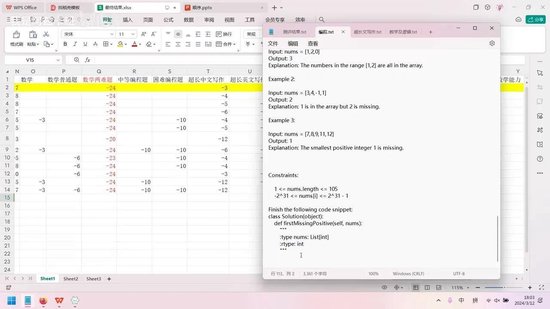
此外,我还设置了一些编程题目,这些题目选自力扣平台,难度较高。但这也反映出一个现象:当前编程竞赛题目(如ICPC、ACM等)的实际意义有限。这类题目在网上都能找到现成答案,更像是测试记忆而非能力。
本次测评中,AI的表现进一步验证了我的观点。三个模型在编程题上均获得满分,且代码的时间复杂度和空间复杂度表现优异。这表明算法问题已无需人工解决。
最后,我还准备了两道英文超长写作题目。
首先是英文短文写作部分,基于之前的雅思考试题目,各模型表现均较为出色,因此未在此详细列出,均给予满分10分。
接下来是英文长文写作测评,我搜集了相关资料并设定为剧本创作任务。测评结果显示,各模型在此项表现差异显著。例如,百度4.0尽管被明确要求用英文回答,却仍使用中文回复,因此扣除全部12分。
GPT模型表现优异,剧本设计人物生动、情节合理且趣味性强。相比之下,多数模型仅简单概括文章内容,未能达到电影情节设计的要求,整体表现欠佳。其中百度4.0因语言不符成为最差案例。
最后进行总结。
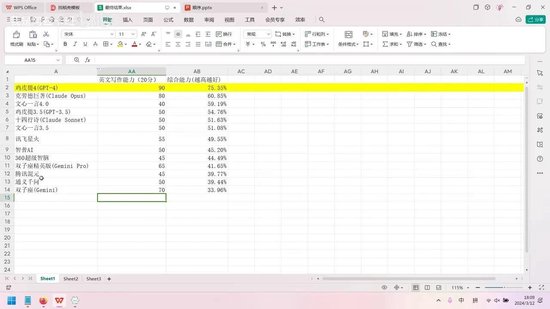
若需处理中文内容,文心一言4.0是最佳选择,其信息提取能力尤为突出,适用于文章总结或要点归纳等任务。在中文写作方面,GPT-4表现更优,但文心一言同样出色。对于中文文本相关需求,文心一言4.0完全能够胜任,且其3.5版本与4.0版本差距显著,会员费用物有所值。相比之下,360和腾讯的模型表现欠佳。
在逻辑分析方面,无论是数学能力还是逻辑推理,GPT-4均为最强选择。若无法使用GPT-4,文心一言4.0是最佳替代方案。智普AI虽在逻辑能力上有所建树,但数学能力较弱,综合表现不及文心一言。
编程方面,文心一言表现卓越,完全不逊色于GPT和克劳德模型。至于英文写作,GPT-4仍为首选,若无法使用,讯飞星火是次优选择,但其处理长文本的能力有限。
文心一言4.0表现最差,因其总是提供中文回答,令人不甚满意。
接下来总结各模型是否值得开通会员:
- GPT-4现已免费,无需开通会员。
- 克劳德的Opus与Sonnet版本在综合能力上存在显著差距,因此会员服务具有一定价值。
- 文心一言与3.5版本差距较大,会员服务意义重大。文心一言可媲美克劳德巨著,而3.5版本则与克劳德十四行诗相当。
- GPT系列中3.5和4版本仍保持领先地位。
综合能力最强的当属文心一言4.0,使用最为便捷。若辅以讯飞星火处理英文文案,则完全够用。
至于智普AI等模型,无论中文、英文能力,还是算法、逻辑及数学表现均不尽如人意,不建议使用。
本次测评的价值显而易见。
这是智谱AI官方公布的模型能力展示。
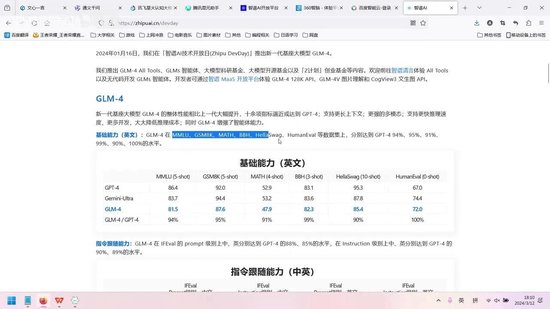
该模型号称性能可比肩GPT-4,声称达到其90%的水平。然而,根据我的测评结果,它与GPT-4的实际差距相当显著。究其原因,问题出在测试数据集上。这些数据集说实话我此前闻所未闻,但为何被广泛采用作为评测标准呢?这本质上是一个系统性漏洞。
以学术论文为例:最初学者撰写论文是为了记录重要研究成果,但后来论文数量逐渐演变为衡量标准。于是人们无论有无实质贡献都开始大量产出论文,最终导致学术灌水现象。
同理,这些测试数据集本应用于评估模型性能,但部分企业却专门针对这些特定数据集进行优化。虽然模型在这些数据集上表现优异,但实际应用效果却不尽如人意,因为其优势仅限于特定测试场景。
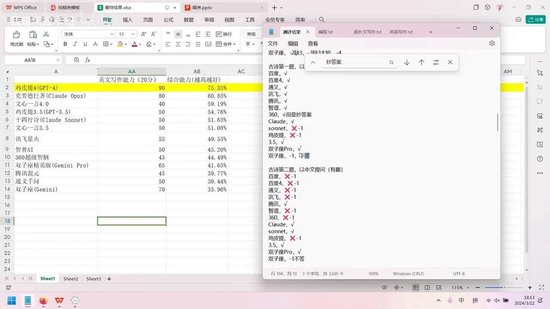
可以说,这个系统基本涵盖了日常生活中常用的功能,如文案撰写,这已包含在中英文写作模块中。此外,编程、逻辑分析、数学等常见需求也都包含在内。有人可能会问,为何不包含生物、医药、法律等领域的内容?因为这些领域的核心本质仍是信息提取和分析,与阅读理解题的性质相同。
对于这个模型,不应将其视为人类,而要理解其知识储备是无限的,只是缺乏运用知识的能力。因此,询问金融问题与语文问题的效果是相同的。
一个有趣的现象是,某些模型如360超级智脑会出现抄袭答案的情况。这些抄袭答案的模型在测评中都被判为零分。抄袭答案表明模型对题目缺乏独立理解,若更换题目便无法解答。允许的做法是上网搜索后自行总结,或至少改变表述方式以证明理解。直接抄袭答案或拒绝回答的模型均被判为零分,因为这对实际应用毫无意义。
接下来,我们继续分析智谱AI的测评结果。
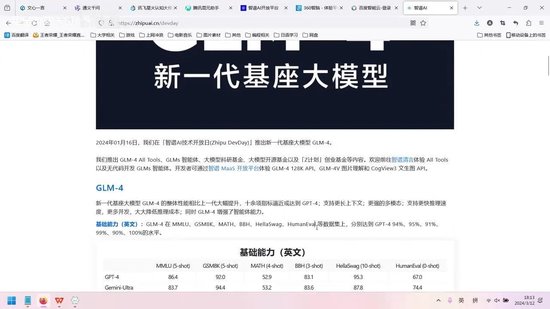
从测评能力来看,无论是中文还是英文,该模型的表现似乎都超越了GPT-4。然而,这一结论仅基于特定数据集。在实际应用层面,智谱AI的表现仍有较大提升空间。
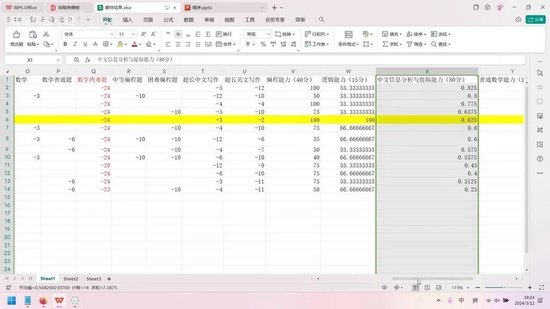
无论是中文还是英文,其表现均不及GPT出色。以中文信息分析与提取能力为例,其水平远逊于GPT,甚至不及百度。中文写作能力同样不尽如人意。
他怎敢在此宣称能够超越GPT4?或许仅在某些对齐能力或特定任务上有所突破,但实际应用并无显著价值。本文章仅针对文本能力进行了测评。




网友留言(0)